支付宝开源一骑绝尘的新序列化框架 —— Fury
最近蚂蚁旗下支付宝开源了一款重磅的产品,一个号称超过现有序列化框架 170x 性能的序列化框架 Fury。根据官方的介绍 Fury 是一个极快的多语言序列化框架,由 jit(即时编译)和零拷贝提供支持,提供高达 170 倍的性能和终极易用性。
特性
-
支持多种语言: Java/Python/C++/Golang/Javascript; -
零拷贝:受 pickle5和堆外读 / 写启发的跨语言带外序列化; -
高性能:高度可扩展的 JIT框架,可在运行时以异步多线程方式生成序列化器代码以加速序列化,通过以下方式提供 20-170 倍的加速:-
通过生成代码中的内联变量减少内存访问。 -
通过生成代码中的内联调用减少虚拟方法调用。 -
减少条件分支。 -
减少哈希查找。
-
-
多种二进制协议:对象图、行格式等。 -
直接替换 JDK/Kryo/Hessian等Java序列化框架,无需修改任何代码,但速度提高 100 倍。它可以极大地提高高性能 RPC 调用、数据传输和对象持久化的效率。 -
JDK序列化 100% 兼容,原生支持 java 自定义序列化writeObject/readObject/writeReplace/readResolve/readObjectNoData。 -
支持 golang的共享和循环引用对象序列化。 -
支持 golang自动对象序列化。
性能
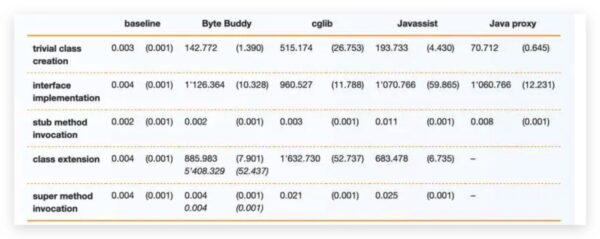
官方给了一个详细的测试案例,不管是从序列化还是反序列化,效果都是一骑绝尘的,如下所示

上图中第一行是序列化的测试,可以看到在对比 Fury,Hession,JDK,Kryo 的情况下,使用同样的用例,Fury 的效果要甩其他几种好几条街。
同样的在下面的反序列化中,Fury 的效果也是杠杠的,详细的性能测试数据,大家感兴趣可以在这里看到 https://github.com/alipay/fury/tree/main/docs/benchmarks,
测试
Java 用例
package com.example.furytest.demo;
import io.fury.Fury;
import io.fury.Language;
import io.fury.ThreadSafeFury;
/**
* <br>
* <b>Function:</b><br>
* <b>Author:</b>@author Silence<br>
* <b>Date:</b>2023-07-24 21:50<br>
* <b>Desc:</b>无<br>
*/
public class StudentDTO {
private Long id;
private String name;
private int age;
... 省略 getter setter
public static void main(String[] args) {
StudentDTO studentDTO = new StudentDTO();
studentDTO.setAge(18);
studentDTO.setName("Java极客技术");
studentDTO.setId(1L);
Fury fury = Fury.builder().withLanguage(Language.JAVA).build();
fury.register(StudentDTO.class);
byte[] bytes = fury.serialize(studentDTO);
System.out.println(fury.deserialize(bytes));
ThreadSafeFury fury2 = Fury.builder().withLanguage(Language.JAVA)
// Allow to deserialize objects unknown types,
// more flexible but less secure.
// .withSecureMode(false)
.buildThreadSafeFury();
fury2.getCurrentFury().register(StudentDTO.class);
byte[] bytes2 = fury2.serialize(studentDTO);
System.out.println(fury2.deserialize(bytes2));
}
}

构造 Fury 的时候我们可以构造单线程 Fury 或者线程安全的 Fury,分别如下
创建单线程 Fury
Fury fury = Fury.builder()
.withLanguage(Language.JAVA)
// 是否开启循环引用,如果并不需要的话可以关闭,提升性能
.withRefTracking(false)
// 是否压缩 Integer 或者 Long 类型的数字
// .withNumberCompressed(true)
// 类型前后一致性兼容
.withCompatibleMode(CompatibleMode.SCHEMA_CONSISTENT)
// .withCompatibleMode(CompatibleMode.COMPATIBLE)
// 是否开启多线程编译
.withAsyncCompilationEnabled(true)
.build();
byte[] bytes = fury.serialize(object);
System.out.println(fury.deserialize(bytes));
创建线程安全的 Fury
ThreadSafeFury fury = Fury.builder()
.withLanguage(Language.JAVA)
.withRefTracking(false)
.withCompatibleMode(CompatibleMode.SCHEMA_CONSISTENT)
.withAsyncCompilationEnabled(true)
.buildThreadSafeFury();
byte[] bytes = fury.serialize(object);
System.out.println(fury.deserialize(bytes));
零拷贝用例
我们先看下什么是零拷贝,基于 ChatGPT 的回答,零拷贝的含义如下
零拷贝(Zero Copy)是一种优化技术,旨在减少数据在内存中的复制操作,提高数据传输和处理的效率。
在传统的拷贝操作中,当数据从一个位置(例如磁盘、网络等)传输到另一个位置(例如应用程序的内存),通常需要将数据从源位置复制到中间缓冲区,然后再从中间缓冲区复制到目标位置。这种复制操作会占用时间、CPU 和内存资源。
而零拷贝技术通过避免这些不必要的数据复制,从而提高数据传输和处理的效率。具体而言,它允许数据在不进行额外复制的情况下直接从源位置传输到目标位置。
在实现零拷贝时,通常会使用一些特定的技术和 API,如操作系统提供的零拷贝接口、内核缓冲区、DMA(直接内存访问)等。这些技术可以减少或消除不必要的数据复制,从而提高系统的性能和吞吐量。
零拷贝技术在处理大量数据的场景中特别有用,例如高性能网络传输、文件 I/O、数据库操作等。它可以减少不必要的 CPU 负担和内存消耗,并提高数据的传输速度和处理效率。
package com.example.furytest.demo;
public class StudentDTO {
private Long id;
private String name;
private int age;
public static void main(String[] args) {
Fury fury = Fury.builder()
.withLanguage(Language.JAVA)
.build();
List<Object> list = Arrays.asList("str", new byte[1000], new int[100], new double[100]);
Collection<BufferObject> bufferObjects = new ArrayList<>();
byte[] bytes = fury.serialize(list, e -> !bufferObjects.add(e));
List<MemoryBuffer> buffers = bufferObjects.stream().map(BufferObject::toBuffer).collect(Collectors.toList());
System.out.println(fury.deserialize(bytes, buffers));
}
}
这段代码的主要目的是将一个包含不同类型对象的列表进行序列化和反序列化操作,其中序列化操作通过 Fury 库实现零拷贝。
以下是代码的主要步骤说明:
-
在 main方法中创建一个Fury实例,该实例用于进行序列化和反序列化操作:
Fury fury = Fury.builder()
.withLanguage(Language.JAVA)
.build();
-
创建一个包含不同类型对象的列表 list:
List<Object> list = Arrays.asList("str", new byte[1000], new int[100], new double[100]);
-
创建一个存储 BufferObject的集合bufferObjects,用于在序列化过程中收集需要单独处理的对象(即非基本类型对象):
Collection<BufferObject> bufferObjects = new ArrayList<>();
-
使用 Fury 的 serialize方法对列表进行序列化,并传入一个 lambda 表达式来判断对象是否需要单独处理(即加入bufferObjects集合):
byte[] bytes = fury.serialize(list, e -> !bufferObjects.add(e));
-
使用 Java 8 的流操作将 bufferObjects集合转换为MemoryBuffer类型集合buffers:
List<MemoryBuffer> buffers = bufferObjects.stream()
.map(BufferObject::toBuffer).collect(Collectors.toList());
-
使用 Fury 的 deserialize方法对序列化的字节数组bytes进行反序列化,并传入buffers集合用于零拷贝操作:
System.out.println(fury.deserialize(bytes, buffers));
这段代码主要演示了如何使用 Fury 库进行零拷贝的序列化和反序列化操作,其中非基本类型对象被存储在 BufferObject 类中,以实现更高效的数据传输和处理。
总结
Fury 目前刚刚开源不久,社区也是才刚刚开始,文档内容以及 issue 都还很多,但是我相信随着时间的推移,这么优秀的开源框架迟早会发展起来的,毕竟在序列化这块有着一骑绝尘的性能。
另外一点也告诉我们即使在序列化技术已经很成熟的今天,依然可以有更好的切入点做出更好的序列化框架,只能说技术无止境。







发表评论