18张图教你使用 Canal Adapter 同步 MySQL 数据到 ES8,建议收藏!
要将 MySQL 的数据同步到 ES8 中总共有如下几个配置,每一个都是必须的
1.MySQL 开启 binlog 日志,并且选择 ROW 模式;
2.初始化 Canal 数据库,并且增加对应的数据库账号和开启 slave 权限;
3.启动 Canal Server 和 Canal Adapter 并配置对应 ES8 的适配器;
4.安装 ES8 并且提前创建对应的数据索引,否则同步不成功。
MySQL 相关配置
检查 MySQL 当前是否开启 binlog,执行如下命令
mysql> show variables like '%log_bin%';
如果没有开启,则通过修改 my.cnf 配置文件来进行开启,并且配置成 ROW 模式。
开启 binlog
cat /etc/my.cnf
# log_bin
[mysqld]
log-bin = /var/lib/mysql/binlogs/mysql-bin #开启binlog binlog-format = ROW #选择row模式 server_id = 1 #配置mysql replication需要定义,不能和canal的slaveId重复
配置 Canal 专属账号
创建一个独立的 canal 账号,并且授权查询和 SLAVE 以及 REPLICATION 权限,账号密码可以自定义,这里都设置成了 canal,这个账号密码后续配置 canal 的时候都会用到。
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;安装 Canal
wget https://github.com/alibaba/canal/releases/download/canal-1.1.7/canal.deployer-1.1.7.tar.gz
wget https://github.com/alibaba/canal/releases/download/canal-1.1.7/canal.adapter-1.1.7.tar.gz
Canal Adapter 数据订阅的方式支持两种,直连 Canal Server 或者 订阅 Kafka/RocketMQ 的消息,我们这里是单机,所以直连 Server。
启动 Canal Server
解压 canal.deployer 压缩包,修改 deployer/conf/example/instance.properties 配置文件,将下面的属性配置成自己设置的值
canal.instance.master.address=127.0.0.1:3306
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal然后启动 Server
./bin/startup.sh查看日志
# 查看 server 日志
tail -f logs/canal/canal.log
# 查看 instance 日志
tail -f logs/example/example.log配置 Canal Adapter
Canal Adapter 的配置分配启动器的配置文件和适配器的配置问题,启动器的配置文件为 application.yml 主要用来配置协议以及配置使用什么适配器。
启动器配置
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
flatMessage: true
zookeeperHosts:
syncBatchSize: 1000
retries: -1
timeout:
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
canal.tcp.server.host: 127.0.0.1:11111
canal.tcp.zookeeper.hosts:
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
# kafka consumer
# kafka.bootstrap.servers: 127.0.0.1:9092
# kafka.enable.auto.commit: false
# kafka.auto.commit.interval.ms: 1000
# kafka.auto.offset.reset: latest
# kafka.request.timeout.ms: 40000
# kafka.session.timeout.ms: 30000
# kafka.isolation.level: read_committed
# kafka.max.poll.records: 1000
# rocketMQ consumer
# rocketmq.namespace:
# rocketmq.namesrv.addr: 127.0.0.1:9876
# rocketmq.batch.size: 1000
# rocketmq.enable.message.trace: false
# rocketmq.customized.trace.topic:
# rocketmq.access.channel:
# rocketmq.subscribe.filter:
# rabbitMQ consumer
# rabbitmq.host:
# rabbitmq.virtual.host:
# rabbitmq.username:
# rabbitmq.password:
# rabbitmq.resource.ownerId:
srcDataSources:
defaultDS:
url: jdbc:mysql://127.0.0.1:3306/ry-vue?useUnicode=true
username: root
password: 123456
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: es8
key: es-key
hosts: https://127.0.0.1:9200 # 127.0.0.1:9200 for rest mode
properties:
mode: rest # transport or rest
security.auth: elastic:oQuOvvZWZ_Yl*MP4Qdx+
security.ca.path: /etc/canal/http_ca.crt
cluster.name: docker-cluster
- name: logger
# - name: rdb
# key: mysql1
# properties:
# jdbc.driverClassName: com.mysql.jdbc.Driver
# jdbc.url: jdbc:mysql://127.0.0.1:3306/mytest2?useUnicode=true
# jdbc.username: root
# jdbc.password: 121212
# druid.stat.enable: false
# druid.stat.slowSqlMillis: 1000
# - name: rdb
# key: oracle1
# properties:
# jdbc.driverClassName: oracle.jdbc.OracleDriver
# jdbc.url: jdbc:oracle:thin:@localhost:49161:XE
# jdbc.username: mytest
# jdbc.password: m121212
# - name: rdb
# key: postgres1
# properties:
# jdbc.driverClassName: org.postgresql.Driver
# jdbc.url: jdbc:postgresql://localhost:5432/postgres
# jdbc.username: postgres
# jdbc.password: 121212
# threads: 1
# commitSize: 3000
# - name: hbase
# properties:
# hbase.zookeeper.quorum: 127.0.0.1
# hbase.zookeeper.property.clientPort: 2181
# zookeeper.znode.parent: /hbase
# - name: kudu
# key: kudu
# properties:
# kudu.master.address: 127.0.0.1 # ',' split multi address
# - name: phoenix
# key: phoenix
# properties:
# jdbc.driverClassName: org.apache.phoenix.jdbc.PhoenixDriver
# jdbc.url: jdbc:phoenix:127.0.0.1:2181:/hbase/db
# jdbc.username:
# jdbc.password:简单说明srcDataSources:表示需要同步的数据库的配置信息
canalAdapters:canal 的适配器配置,下面可以配置多个 instance
instance:需要跟我们上面启动 Canal Server 里面的 instance 一致,默认为 example
outerAdapters:表示我们需要使用的适配器的列表
name:表示我们使用的是哪个适配器,es8 表示使用的是 es8 适配器,其他的可以参考解压后的 conf 下面的目录名称
properties:properties 下面会有几个重要的配置,分别是协议类型 mode,ES8 的账号密码 security.auth,以及集群名称 cluster.name,还有一个 security.ca.path CA 证书路径,这一项在官方的代码中输出没有的,因为官方并不支持 ES8 的 TLS 认证,对应 ES8 的部署的时候需要关闭 ES8 的安全功能,我这边自己基于源码做了一下改造支持,感兴趣可以看 Github 上面的源码 https://github.com/zhuSilence/canal/commit/d5dba78b78183b7de1472cdc6500ac2c8dba6b66。
适配器配置
在上面的启动器的配置中我们已经配置了 ES8 作为适配器,那具体要同步的是哪张表,以及对应的 ES 中是索引是哪个怎么配置呢?这些配置就放在适配器的配置里面,每一个适配器的配置都是一个想要同步到 ES 的模板配置。
这里假设我有两张表,结构如下,一张主表 ead_advertiser,一张从表 ead_advertiser_setting,是一个一对多的关系。
CREATE TABLE `ead_advertiser` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '广告主信息表',
`user_id` bigint(20) NOT NULL COMMENT '关联的登录用户 id',
`advertiser_name` varchar(45) NOT NULL COMMENT '广告主主体名称',
`advertiser_email` varchar(255) NOT NULL COMMENT '广告主主体邮箱',
`advertiser_phone` varchar(20) NOT NULL COMMENT '广告主主体联系方式',
`advertiser_type` tinyint(1) unsigned NOT NULL DEFAULT '0' COMMENT '广告主类型0 广告主 1 代理商',
`status` tinyint(4) unsigned NOT NULL DEFAULT '1' COMMENT '状态-1 删除 0 禁用 1 正常',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
`gmt_update` datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_email` (`advertiser_email`) COMMENT '邮箱唯一索引',
UNIQUE KEY `uk_phone` (`advertiser_phone`) COMMENT '手机号唯一索引'
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='广告主信息表';
CREATE TABLE `ead_advertiser_setting` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ead_advertise 配置信息表主键',
`advertiser_id` bigint(20) NOT NULL COMMENT '主表 id',
`setting_key` varchar(255) NOT NULL COMMENT '扩展字段 key',
`setting_value` varchar(255) DEFAULT NULL COMMENT '扩展字段 value',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
`gmt_update` datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_advertiser_id_setting_key` (`advertiser_id`,`setting_key`) USING BTREE COMMENT 'key 唯一索引',
KEY `idx_advertiser_id` (`advertiser_id`) COMMENT '广告主 id 索引'
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='广告主信息扩展表';数据如下所示

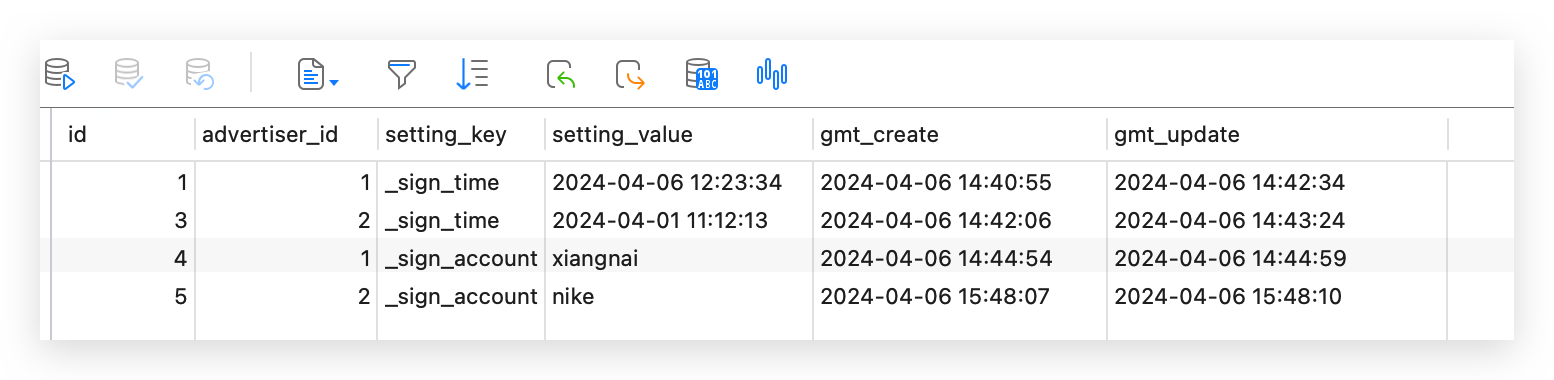
现在想把这两张表形成一张大宽表,setting_key 里面的内容作为一个独立的列拼接在主表上面,然后将拼接后的数据同步到 ES 中。

转换的 SQL 如下
SELECT
a.id AS _id,
a.user_id AS user_id,
a.advertiser_name AS advertiser_name,
a.advertiser_email AS advertiser_email,
a.advertiser_phone AS advertiser_phone,
a.advertiser_type AS advertiser_type,
a.status AS status,
a.gmt_create AS gmt_create,
a.gmt_update AS gmt_update,
c.advertiser_id AS advertiser_id,
c._sign_time AS _sign_time,
c._sign_account AS _sign_account
FROM
ead_advertiser a
LEFT JOIN (
SELECT
b.advertiser_id AS advertiser_id,
max((
CASE
b.setting_key
WHEN '_sign_time' THEN
b.setting_value ELSE ''
END
)) AS _sign_time,
max((
CASE
b.setting_key
WHEN '_sign_account' THEN
b.setting_value ELSE ''
END
)) AS _sign_account
FROM
ead_advertiser_setting b
GROUP BY
b.advertiser_id
) c ON ((
a.id = c.advertiser_id
))那么对应的适配的配置如下所示
dataSourceKey: defaultDS
destination: example
outerAdapterKey: es-key
groupId: g1
esMapping:
_index: search-advertiser_info
_id: _id
upsert: true
#pk: id
sql: "SELECT a.id AS _id,a.user_id AS user_id,a.advertiser_name AS advertiser_name,a.advertiser_email AS advertiser_email,a.advertiser_phone AS advertiser_phone,a.advertiser_type AS advertiser_type,a.status AS status,a.gmt_create AS gmt_create,a.gmt_update AS gmt_update,c.advertiser_id AS advertiser_id,c._sign_time AS _sign_time,c._sign_account AS _sign_account FROM ead_advertiser a LEFT JOIN (SELECT b.advertiser_id AS advertiser_id, max((CASE b.setting_key WHEN '_sign_time' THEN b.setting_value ELSE '' END )) AS _sign_time,max((CASE b.setting_key WHEN '_sign_account' THEN b.setting_value ELSE '' END )) AS _sign_account FROM ead_advertiser_setting b GROUP BY b.advertiser_id ) c ON ((a.id = c.advertiser_id ))"
# objFields:
# _labels: array:;
#etlCondition: " where a.gmt_update>='{0}'"
commitBatch: 1简单说明:
dataSourceKey: defaultDS
destination: example
outerAdapterKey: es-key
groupId: g1
上面的几个配置,都需要跟启动器里面的配置保持一致。
esMapping:该配置是表示的是如何将 MySQL 的数据同步到 ES 中,配置比较复杂,其中
_index 表示 ES 的索引(需要提前创建);
_id 和 pk 二选一配置,表示使用查询出来的哪个字段作为唯一值;
upsert 表示对应主键的数据不存在的时候执行插入动作,存在的时候执行更新动作;
sql:表示要同步的数据,这个的 SQL 形式要求会比较严格
sql 支持多表关联自由组合, 但是有一定的限制:
- 主表不能为子查询语句
- 只能使用
left outer join即最左表一定要是主表 - 关联从表如果是子查询不能有多张表
- 主
sql中不能有where查询条件(从表子查询中可以有where条件但是不推荐, 可能会造成数据同步的不一致, 比如修改了where条件中的字段内容) - 关联条件只允许主外键的’=’操作不能出现其他常量判断比如:
on a.role_id=b.id and b.statues=1 - 关联条件必须要有一个字段出现在主查询语句中比如:
on a.role_id=b.id其中的a.role_id或者b.id必须出现在主select语句中
全量 ETL
配置好了启动器和适配器过后,我们就可以启动 Canal Adapter 了,在解压缩的目录中执行如下命令
# 启动启动器
./bin/startup.sh
# 查看日志
tail -f adapter.log输出如下日志,表示启动成功
2024-04-14 16:11:17.746 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Start adapter for canal-client mq topic: example-g1 succeed
2024-04-14 16:11:17.746 [Thread-4] INFO c.a.otter.canal.adapter.launcher.loader.AdapterProcessor - =============> Start to connect destination: example <=============
2024-04-14 16:11:17.746 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterService - ## the canal client adapters are running now ......
2024-04-14 16:11:17.769 [main] INFO c.a.otter.canal.adapter.launcher.CanalAdapterApplication - Started CanalAdapterApplication in 5.912 seconds (JVM running for 7.732)
2024-04-14 16:11:17.963 [Thread-4] INFO c.a.otter.canal.adapter.launcher.loader.AdapterProcessor - =============> Subscribe destination: example succeed <=============首次执行的时候,我们可以通过 ETL 功能,将全量的数据或者根据执行条件过滤后的数据同步到 ES8 中,如果要添加过滤条件,则需要在适配器的配置中增加如下配置和条件。
etlCondition: " where xxx"通过执行如下命令进行全量 ETL
curl -X POST http://127.0.0.1:8081/etl/es8/search-advertiser_info.ymlsearch-advertiser_info.yml 则为适配器文件的名称。
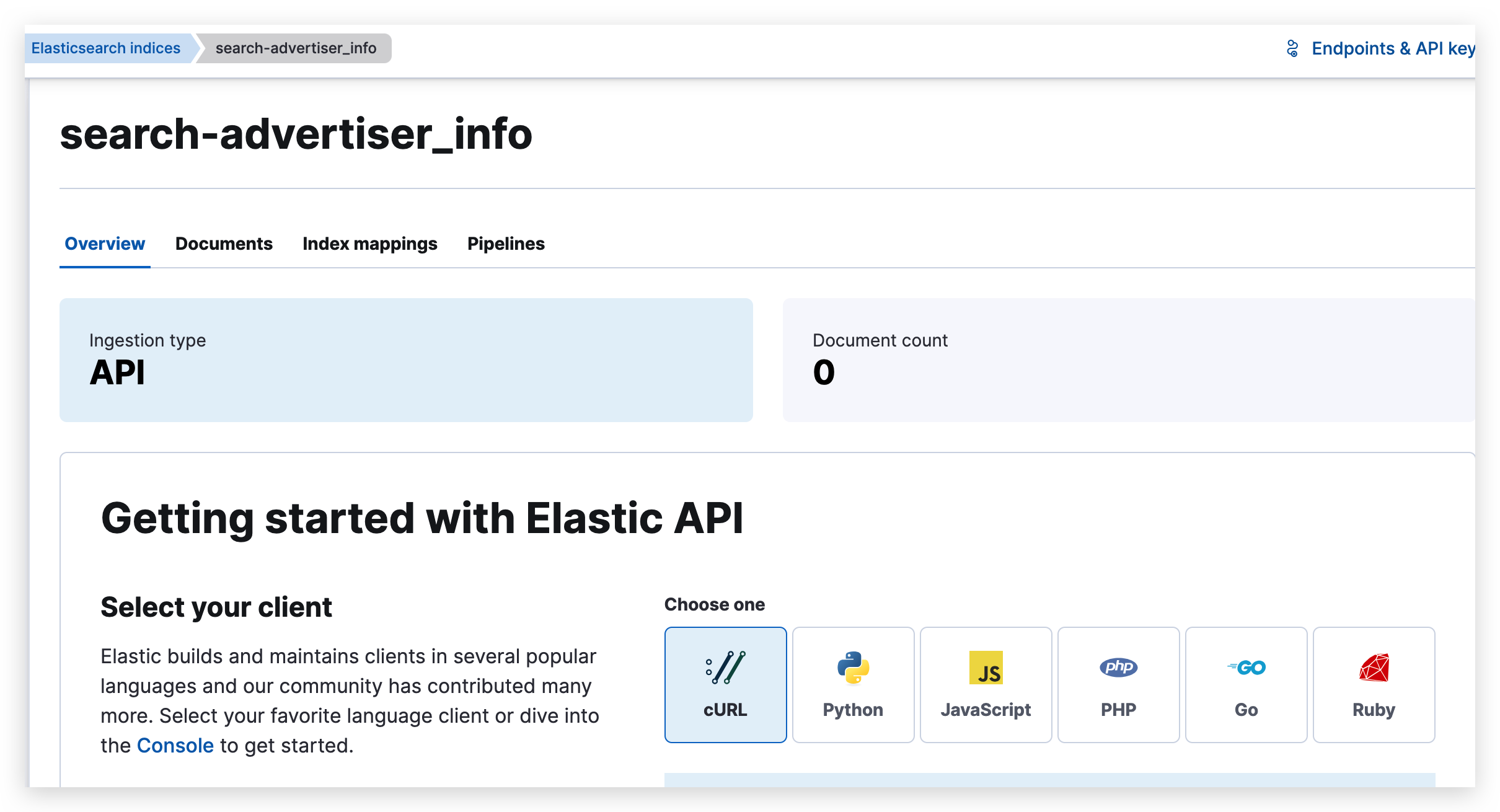
在执行上面的命令之前,我们可以通过 kibana 看到 ES 中对应的索引里面 Document 数量为 0
执行上述命令,日志如下

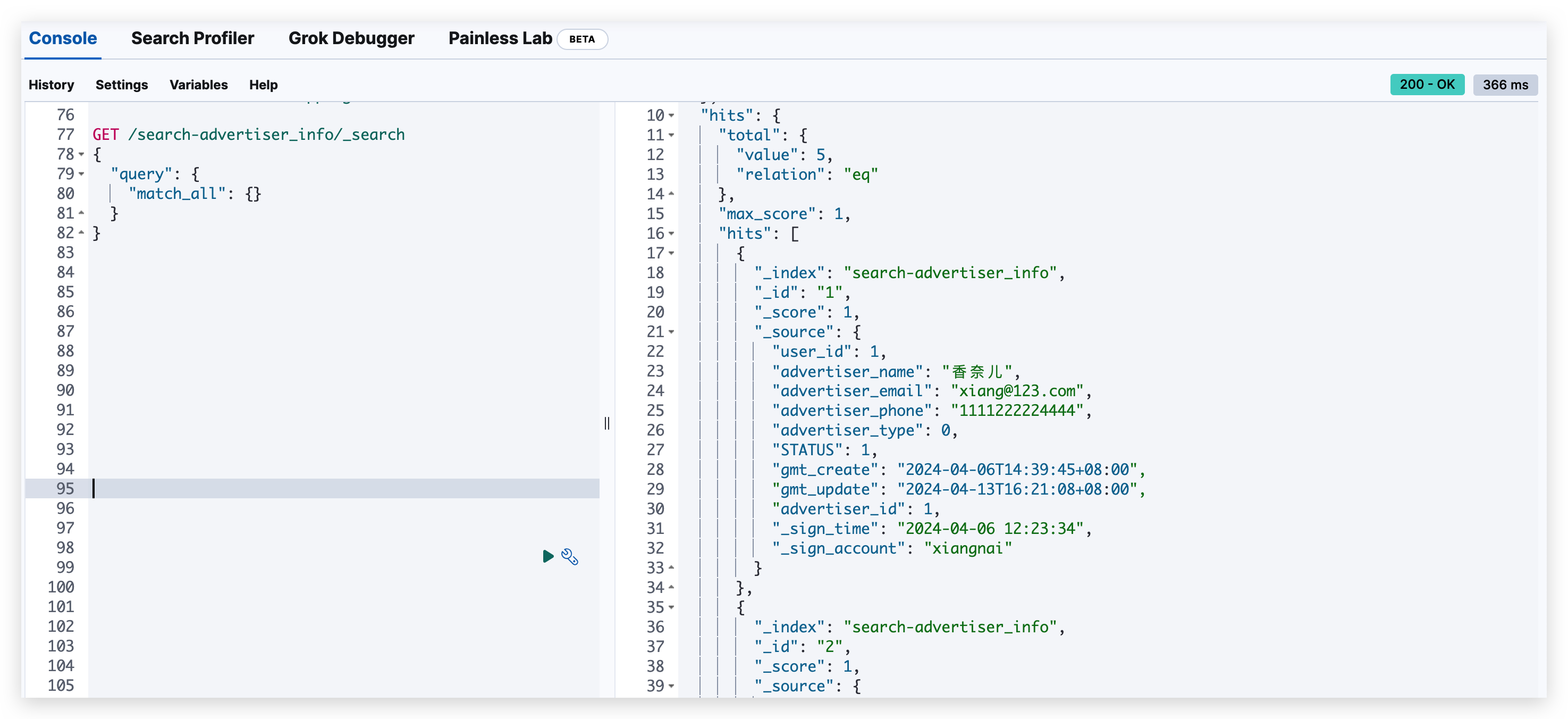
再次查询 ES,发现已经成功写入了五条数据。
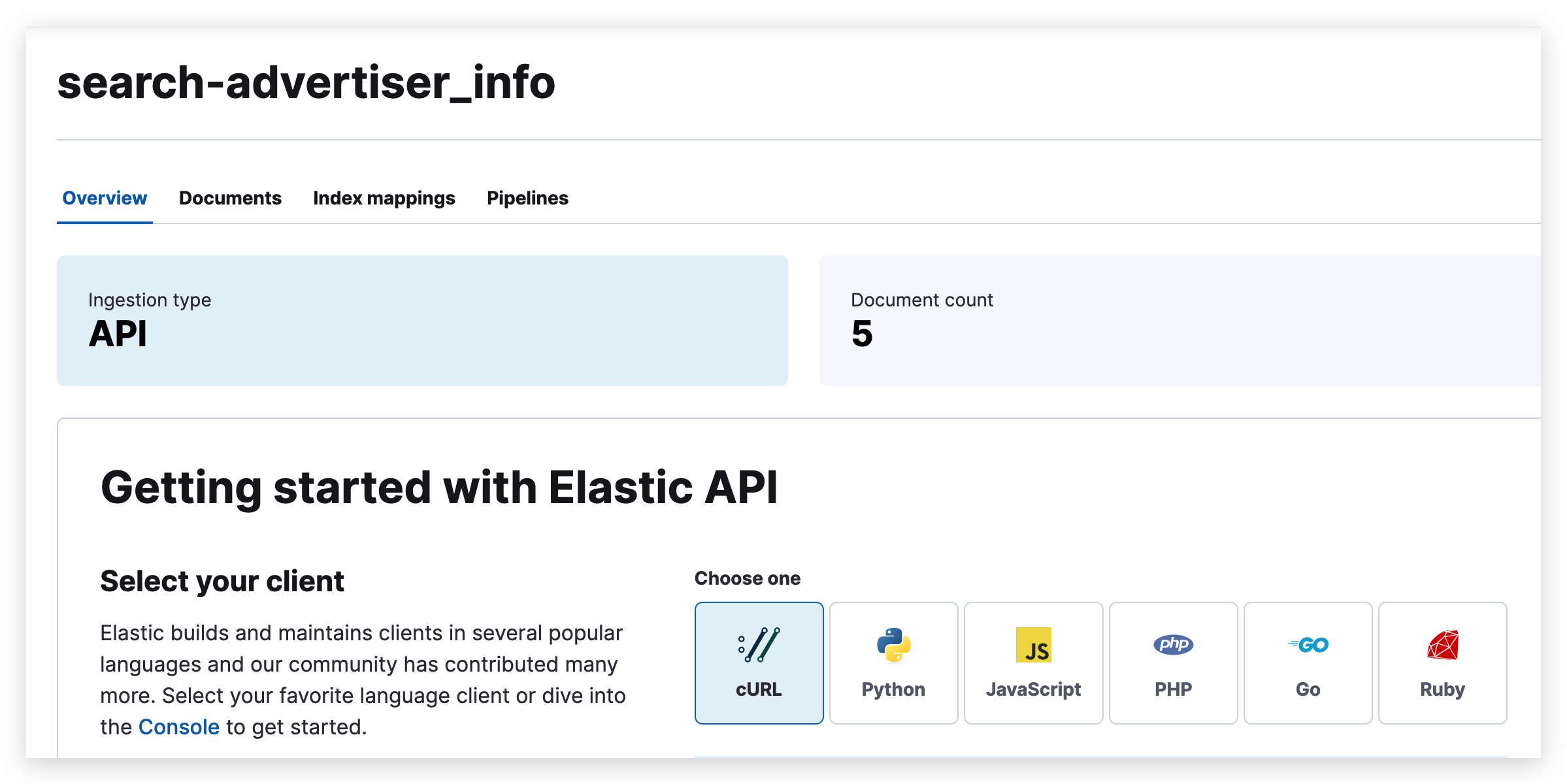
通过查询,可以看到有五条数据
增量同步
这里我们挑选 id 为 4 的这条数据来看下更新后是否会自动同步,当前 id = 4 的数据如下

ES8 中的数据如下

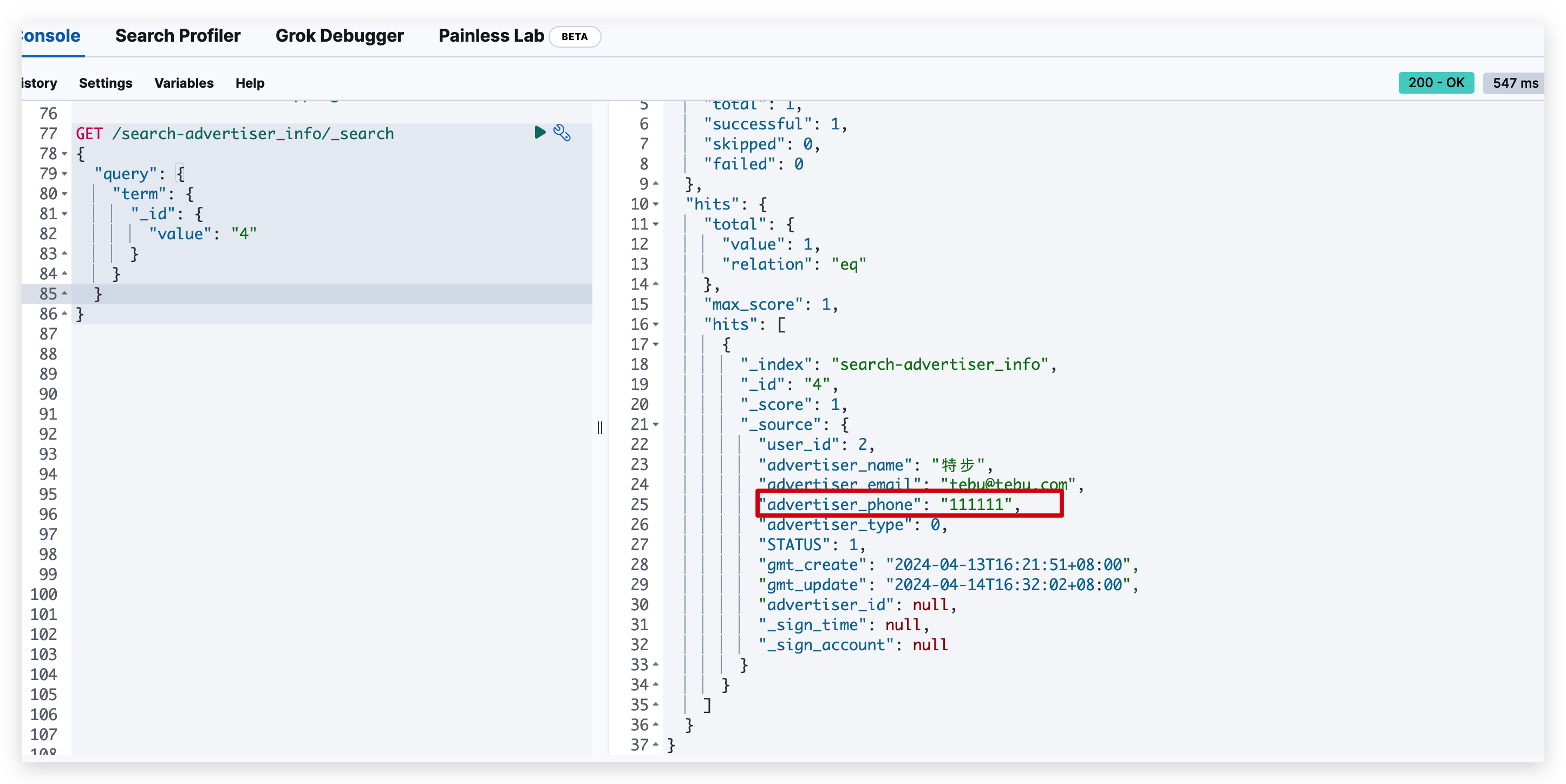
然后我们修改一下 MySQL 中的数据,将 advertiser_phone 修改为 111111,首先数据库中数据已经变了 其次在
其次在 Canal Adapter 的日志中我们也可以看到如下日志
 与此同时我们再次查询
与此同时我们再次查询 ES 发现数据也更新了
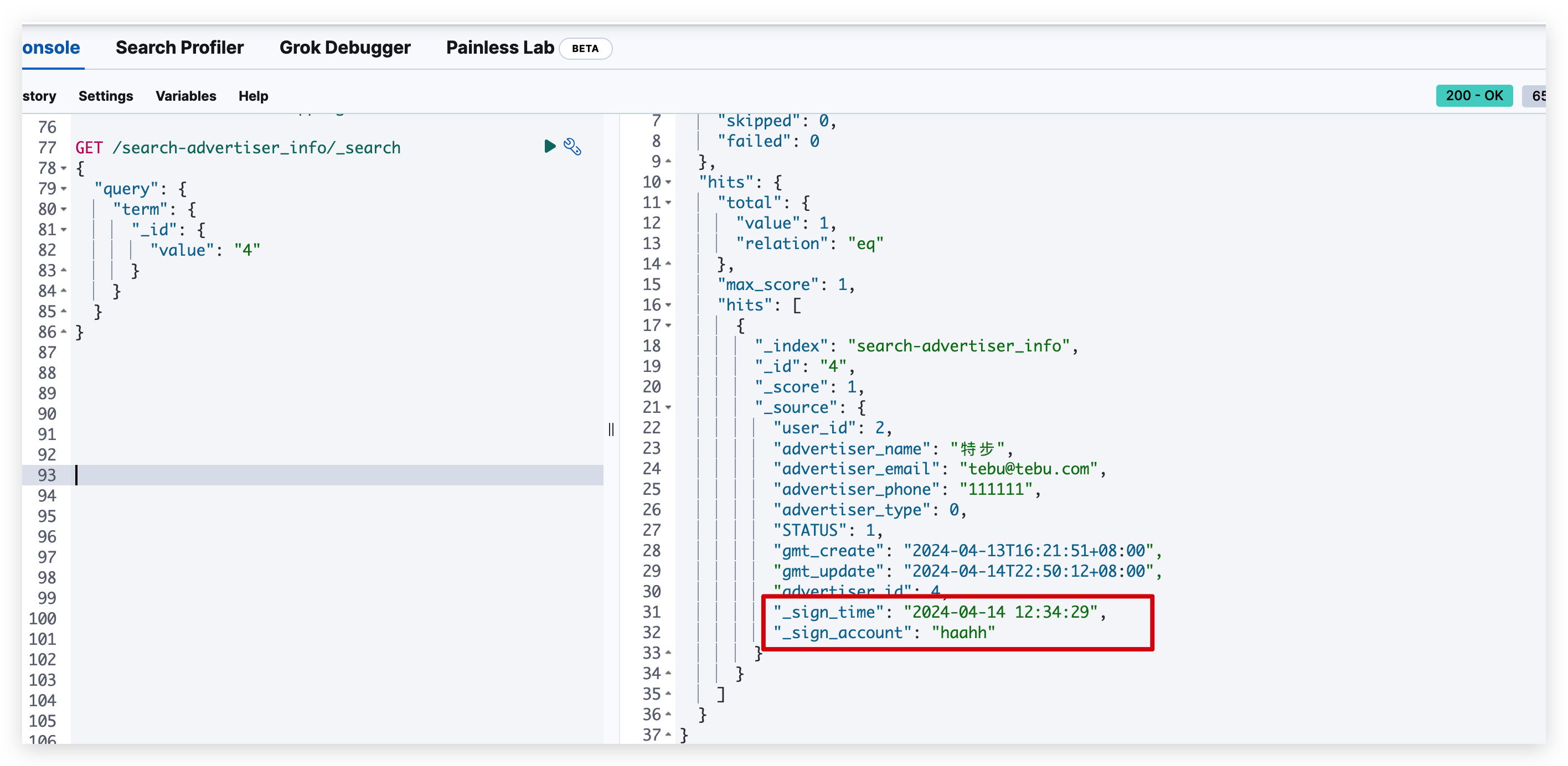
同时我们再通过给 id 为 4 的记录增加两个扩展字段,


ES 中的数据也同步更新了,至此整个数据从MySQL 同步的 ES8 已经基本实现了,后续其他的表也按照这种方式接入即可。
使用 Docker 安装 ES8
Docker 安装 ES8 比较简单,按照官方文档直接操作就好了,这边就不演示了https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html
总结
今天给大家完成的演示了一下如何将 MySQL 的数据通过 Canal Adapter 同步到 ES,功能很强大,但是实操的过程中还是会遇到很多问题的,感兴趣的小伙伴一定要自己动手实操一下,相信会有收获的。









发表评论
Comment List(1)